Background¶
Introduction¶
Distributed Stream Processing Systems (DSPS) take a stream of real time data (often arriving at high speed and large volume) and pass it through a series of operators. These operators perform tasks on the packets of data (often called “tuples” in the literature). These tasks can involve splitting large tuples into smaller ones, counting tuples with particular characteristics (counting hashtags in tweets for example) or combining them with other information from external systems (databases, REST APIs, etc). Operators can then create new tuples and pass them on to operators further along the topology (downstream). Figure 1 shows an example topology.
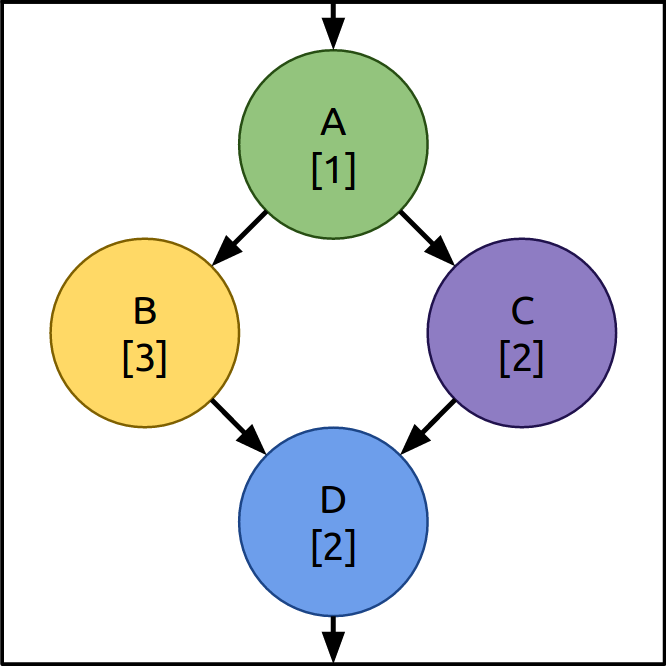
Figure 1 - Example DSPS topology. The numbers in square brackets indicate the level of parallelism (the number of copies) for each operator.
Scaling¶
DSPS provide ways to spread these operators across several machines in a cluster. Each operator can be replicated multiple times in order to handle a large arrival workload. In the topology in Figure 1, operator B takes a long time to process tuples, so there are 3 copies of it to ensure that it does not become a bottle neck. In this way DSPS topologies can be tuned or scaled to ensure they meet throughput (tuples processed per second) or end-to-end latency (the time between a tuple entering the topology and the last tuple resulting from its entry leaving) targets. Conversely, if the input workload into the topology drops then copies of operators can be removed (scaled down) to save on cluster machine resources.
Scheduling¶
Figure 2 shows an example of how the various copies of the operators from the topology shown in Figure 1 could be laid out on the cluster. The process of deciding where to place each copy of the various operators is called scheduling (in Heron this is called packing) and the resulting plan of operators they produce is called a physical plan.
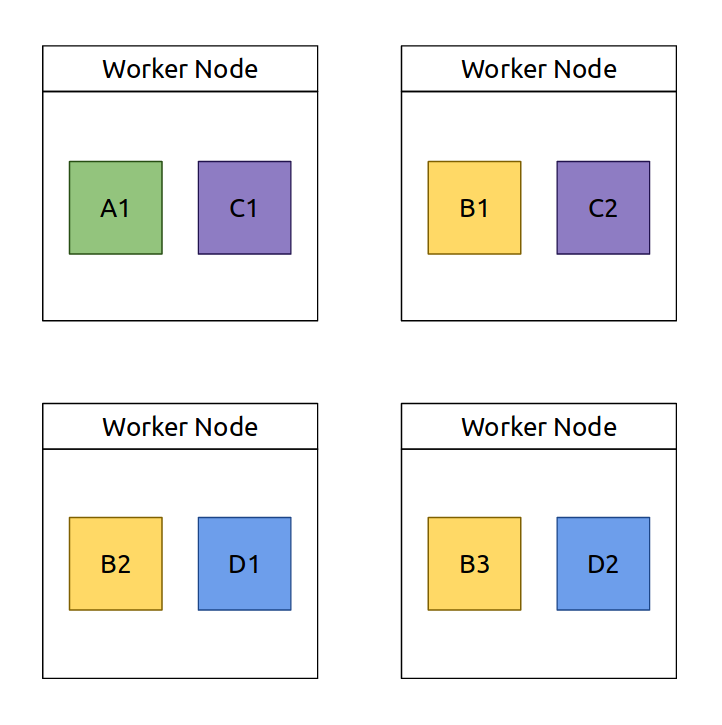
Figure 2 - The layout of operators on the cluster (physical plan). Depending on the DSPS being used worker nodes could be physical machines, virtual machines or containers.
Most modern DSPS, such as Apache Storm and Heron have the ability to easily scale up or scale down the operators of a topology and re-schedule the physical plan. Many scheduling algorithms are available for these systems (each based on optimising for certain criteria) and even more are represented in the literature.
The problem with scaling¶
Most DSPS provide the ability to scale their topologies to meet varying demand. However, as far as we are aware, of all the mainstream DSPS only Heron provides a method to do this scaling automatically. This system, Dhalion, is available in the latest Heron version but has not yet been deployed in a production environment.
As well as Dhalion, there are many examples from the research community of attempts to create automatic scaling systems for DSPS. These are usually based on optimising schedulers that aim to minimise certain criteria, such as the network distance between operators that communicate large tuples or very high volumes of tuples or to ensure no worker node is overloaded by operators that require a lot of processing resources. While the new physical plans these schedulers produce may be optimal compared to the current topology physical plan, none of these systems assess weather the physical plan they produce will actually result in a topology that is capable of meeting a performance target.
The reason this is an issue is that it requires the user (or an automated system) to deploy the physical plan, wait for the deployment to complete, wait for the topology to stabilise and for normal operation to resume, possibly waiting for high traffic to arrive and then analyse the metrics to see if the required performance has been met. Depending on the complexity of the topology and the traffic profile it can take weeks for a production topology to scaled to the correct configuration (right sized).
Reinforcement learning (RL) systems have been proposed as a possible solution to DSPS scaling. However they suffer the same issue as a human user, they need to deploy a physical plan before the cost of the proposed change can be learned. For long running topologies, RL systems may be useful but for short running or newly deployed topologies they offer little advantage over a human user.
Performance modelling¶
If a performance modelling system was available that could assess a proposed physical plan and predict its likely performance before it is deployed. An auto-scaling system (such as Dhalion or a human operator) could iterate to a resource and operator layout plan that is likely to meet a given performance target, without needing to wait for deployment. Of course any modelling system is subject to errors so some deployment and re-deployment will be required, however the number should be significantly reduced.
What’s more, a modelling system would allow several different plans to be assessed in parallel. This means that schedulers optimised for different criteria could be compared simultaneously, which would remove the need for a DSPS user to know before hand which scheduler is best for their particular use case.
A further advantage of a modelling system for DSPS topologies is that of pre-emptive scaling. If the model can accept a prediction of future workload (number of tuples entering the topology) then the auto-scaling system, when paired with a future workload prediction technique, would be able to assess if a future workload will be an issue for the topology’s current physical plan. The system could then use the future workload level to find a physical plan that is likely to meet the performance requirements and deploy this plan before the predicted workload arrives.